 電子發(fā)燒友App
電子發(fā)燒友App



Synchronized multi-spark module (SMSM) for Electronic Ignition Devices (EID)

Multi-spark ignition is very useful especially in the case of startings at low temperature and at low rpm range. Basic idea, is to apply to spark plugs instead of only one spark, a “spark-burst” having big energy. In this case, combustion of air/fuel mixture is much better and the emissions are more reduced. In addition, through burning improvement, the consumption of fuel can be reduced.
Why synchronized multi-spark, or what means this?
Special literature abounds in multi-spark EID schematics. These have in common the fact, as the breaker-points don’t control directly EID, but an oscillator, which will generate a succession of impulses, and these impulses shall command EID. This aproach has two major deficiencies:
1. First spark doesn’t match exactly with the moment of breaking points; so, it has an aleatory delay toward this. This is equivalent to an aleatory modification of ignition advance, which will leads to non-uniform run of engine.
2. At high rpm range, the time between two impulses of multi-spark device can become comparable with the time between breaker-points impulses; this shall lead to an unstable operation of engine, with trepidations and knockings. To avoid this trouble, is necessary to switch-off the multi-spark device when rpm of engine exceeds a certain value.
With these in mind, I imagined the device described forwards.
Few calculations elements
The crankshaft velocity of an internal combustion engine is given by following formula:
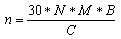
where :
n = revolution speed of engine crankshaft (rpm)
M = strokes number (2 or 4)
N = number of sparks per second (sparks frequency, in Hz)
B = number of ignition coils
C = cylinder number
For usual four stroke engines, with 4 cylinders and a single ignition coil, the formula becomes :
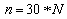
From where :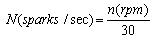

In fig.1 is shown an EID equipped with synchronized multi-spark module.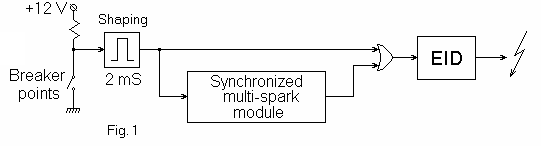
Shaping block has the role to provide fixed length impulses (2 mS) at each breaker-points opening. In this way are eliminated the false impulses which appear due contacts vibrations.
As shown in drawing, shaped impulse triggers directly the EID and act as START impulse for multi-spark module. If rpm of engine is under speed limit, the module will generate a series of supplementary impulses that, through an OR gate, will generate supplementary sparks by EID. When speed limit is reached (for example, 2000 rpm), supplementary impulses stops at module output, thus no supplementary sparks will be generated.
?
Functional description
The module uses for control the shaped impulses from breaker points. The time between two consecutively impulses depends on rpm engine and has the values shown in upper table. 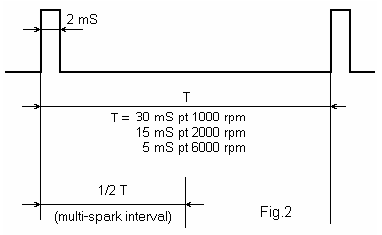
From whole T interval, only in the first half of this will be generated supplementary sparks, after the main spark produced by the breaker points. This is very important, because generating sparks outside of half of the interval, the spinning distributor could apply these sparks to next cylinder, and this could be very harmful for mechanical parts of engine.
??? In fig. 3 is shown the block-diagram of the multi-spark module.
At breaker-points opening, the shaping circuit (not shown in drawing) produces a square impulse having 2 mS. This, named BP, is applied to EID by an OR gate and generate the main spark.
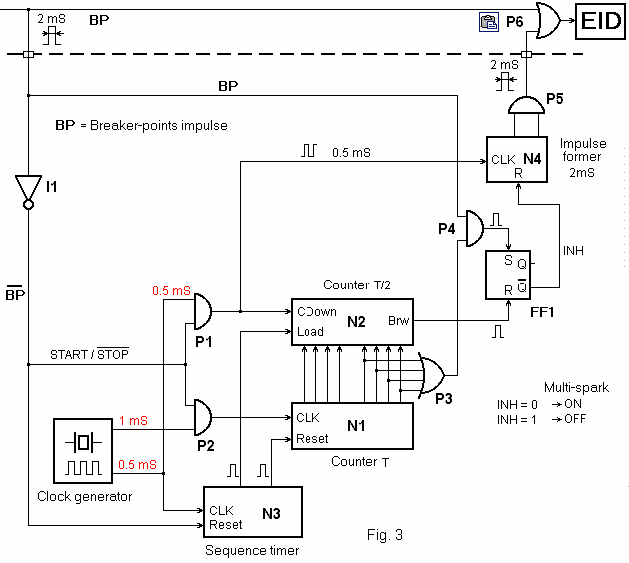
In multi-spark module, during 2 mS interval, a sequence timer (a counter with decoded outputs) accomplishes the initialization of circuits (full operations will be detailed later). When impulse BP disappears, the gate P2 is opened and the counter N1 receives impulses with 1 mS period, from clock generator. This 8 bits counter measures, in fact, the duration between two breaker-points impulses. It can count maximum 255 impulses, each having 1 mS (see the table, this correspond to 120 rpm, far below the free running speed !). At next BP impulse, P2 close and the counting stop. The number stored inside N1 is in fact the time length between two BP impulses.
The sequence timer “copy” the number stored in N1 to N2, after this resets counter N1. When BP becomes low level, N1 restarts the counting. In the same time, the up/down counter N2, starts counting the impulses having 0.5 mS period, which comes via gate P1. It counts down, but with double speed. In this way the counter N2 reach to “0” after T/2 time. The counter N4 and gate P5 makes the impulses for supplementary sparks (2 mS length).
This counter works only if INH signal is at low level. The fip-flop FF1 “marks” the interval T/2 in which will be generated supplementary sparks. It is reseted when N2 reach “0”. The gates P3 and P4 unlock the flio-flop and start supplementary sparks. Also, these gates switch-off the multi-spark function when engine speed limit is reached (in this case, ~ 2000 rpm). How works this ? In the upper table we can see at about 2000 rpm, the time length between two BP impulses is 15 mS.
This means as after a counting cycle, the first 4 bits of counter N1 will be 111 and next 4, 0000. In this case, P3 gate output will be at low level, and the same value for P4 output. The flip-flop FF1 will be not set, and as result, no supplementary sparks. If the speed engine decrease (time length T increase), the last 4 bits of N1 will have at least one 1 and the flip-flop will be set. This allow to appear supplementary sparks until flip-flop will be reseted by borrow impulse of N2.
The module can be maked like a plug-in adapter for an EID.














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論